Im Zusammenspiel von Herstellern und Betreibern von Anlagen und Maschinen stehen im Kontext der Industrie 4.0 Entwicklungen zunehmend Sensor-, Steuer- und Prozessdaten zur Verfügung. Viele Unternehmen sind derzeit noch in der Phase, diese zunächst über Condition Monitoring sichtbar und nutzbar zu machen. Damit verbessern sich aber auch zunehmend die Grundlagen, die OEE (Overall Equipment Effectiveness), die Effizienz sowie die mit dem Betrieb verbundenen Personalaufwände mit Hilfe von KI bzw. Machine Learning zu optimieren. Die Störungsprognose ist dabei nur ein Baustein, aber ein sehr wichtiger, um ungeplante Stillstände zu vermeiden.
Erste Herausforderung
Im Idealfall liegen definierte Meldungen wie etwa Warnungen oder Alarme vor, die als Trainingsdaten für Prognosemodelle genutzt werden können. Dafür müssen aber zuvor entsprechende Schwellwerte und Regeln definiert werden, welche zum einen bei komplexen Anlagen nicht immer sofort auf der Hand liegen und zum anderen bei dynamischen Verhaltensweisen z.B. durch verschiedene Fertigungsprogramme und weitere Einflussfaktoren auch veränderlich sein können bzw. müssen. Daher liegen solche Trainingsdaten nicht immer direkt vor beziehungsweise müssen Normalverhalten und Störungen zunächst sauber separiert werden, um Prognosemodelle nutzen zu können. Auch stellt sich die Frage, wie vieler ‘notwendige Störungen‘ es für das Training entsprechender Modelle bedarf. Die Anzahl ist aus betrieblicher Sicht idealerweise sehr gering, aber ohne hinreichende Beispiele kann auch eine KI nichts erkennen.
Zweite Herausforderung
Getrieben durch den Hype um Machine Learning dominieren in vielen Marketing-Aussagen und Blog-Beiträgen teilweise noch immer komplexe Modelle und Ansätze zur Anomalieerkennung. Diese sind aber für Ingenieure und Verantwortliche für den Betrieb oft nicht nachvollziehbar und können den Blick auf die grundlegenden Bedingungen und Mechanismen zur Anomalieerkennung vernebeln.
Dritte Herausforderung
Prototypische Lösungen, die in der Exploration und im Labor funktionieren, sind zwar häufig schon recht beeindruckend, aber echte Mehrwerte liefern diese nur, wenn sie nahtlos in produktive Umgebungen und Abläufe eingebettet werden.
Lösungsansätze: Welche Anomalien gibt es?
Zunächst sollten die unterschiedlichen Arten und Ursachen von veränderten Dynamiken in realen Maschinen und Anlagen verstanden bzw. unterscheiden werden:
- Umbauten bzw. Ein-/Ausbauten von Komponenten
- Veränderte Steuer-/Fertigungsprogramme
- Tatsächliche Störungen im Prozess vs. Sensor Störungen/Defekte
- Externe Einflussfaktoren wie z.B. Umgebungstemperatur
- Verschleiß und Verschmutzung
Dabei sollten nicht alle der genannten Fälle zu Anomaliemeldungen im Sinne von Alarmen führen. Im Gegenteil: Die ersten beiden sollten idealerweise von den Verfahren für weitere Aufgaben wie Störungsprognose oder adaptive Regelung kompensiert werden.

Was sind eigentlich Anomalien?
Weiterhin ist es sinnvoll, zunächst die generelle Idee hinter der Erkennung von Anomalien zu skizzieren: „An observation which deviates so much from other observations as to arouse suspicions that it was generated by a different mechanism.“ (Hawkins, 1980)
“Therefore, outliers can be thought of as observations that do not follow the expected behavior.“ (A review on outlier/anomaly detection in time series data, 02/2020, Ane Blázquez-García, Angel Conde, Usue Mori, Jose A. Lozano)
Aus diesem Zitat ergeben sich die grundlegenden Elemente:
- ‘other observations‘: zwangsläufig muss immer ein Vergleichszeitraum gewählt werden
- ‘suspicions‘: verdächtig ist, was nicht der Erwartung entspricht
- ‘deviates so much‘: es muss definiert werden, wie hoch Abweichungen sein dürfen, um noch als unverdächtig zu gelten
- ‘different mechanism‘: dies erfordert die Annahme einer bestimmten Verteilung der Messungen (z.B. Normalverteilung)
- Vereinfacht formalisiert folgen die meisten Verfahren also diesem Ansatz: (Tatsächliches Verhalten – Erwartetes Verhalten) > verdächtige Abweichung?
Oftmals werden voreilig komplexe KI/ML Modelle ins Spiel gebracht, die jedoch diese grundlegenden Punkte auch nicht aus der Welt schaffen können. Wird zum Beispiel gerade ein komplexes Modell mit einem Bezugszeitraum trainiert, der Anomalien enthält, kann es sein, dass es diese hervorragend erfasst (also erwartet) und somit keine auffällige Abweichung mehr erkannt wird. Bei allen Verfahren muss zudem mindestens ein Parameter festgelegt werden, der Empfindlichkeit (Sensitivität) und das Risiko von Fehlalarmen (Spezifität) steuert. Damit kommt quasi der eingangs erwähnte Schwellwert wieder durch die Hintertür.
Verfahren zur Anomalie Erkennung
Das Feld der Verfahren ist groß, daher hier nur kurzer Blick auf für Predictive Maintenance mögliche Unterscheidungen:
- Wie zeitnah muss die Erkennung funktionieren, welche Rechenleistung steht zur Verfügung (Stichwort: Edge Computing)?
- Liegen ein- oder mehrdimensionale Daten (Sensor-, Steuer-, Prozess-Signale) vor bzw. müssen gemeinsam betrachtet werden?
- Können die in Frage kommenden Verfahren nur auf ein- oder auch auf mehrdimensionalen Daten arbeiten?
- Sind nur einzelne Zeitpunkte (z.B. Überschreitung einer kritischen Messwert Schwelle) oder Zeitsequenzen (Verhaltensmuster) zu betrachten?
Sind bestimmte Vorverarbeitungen der Signale hilfreich oder notwendig
Nur am Rande: Häufig wird Anomalieerkennung mit ungestütztem Lernen (unsupervised learning) gleichgesetzt, dies ist aber nicht ganz korrekt: Viele Verfahren verwenden Modelle, die auf den Vergleichszeitraum trainiert werden und dann das erwartete Verhalten schätzen beziehungsweise prognostizieren. Darüber hinaus kommen beispielsweise auf der Dichte oder Distanz von Datenpunkten (z.B. Clustering) basierende Verfahren zum Einsatz.
Interaktive und integriert
Bei der Agile IT Management (AIM) wurde daher die Strategie gewählt, die eigene Lösung kontinuierlich, um Verfahren zu erweitern und diese in folgendes Gesamtkonzept zu integrieren:
- Vorverarbeitung: Eine geeignete Transformation der Rohsignale ist häufig entscheidend.
- Automatische Erkennung: Anwendung eines oder mehrerer automatischer Verfahren.
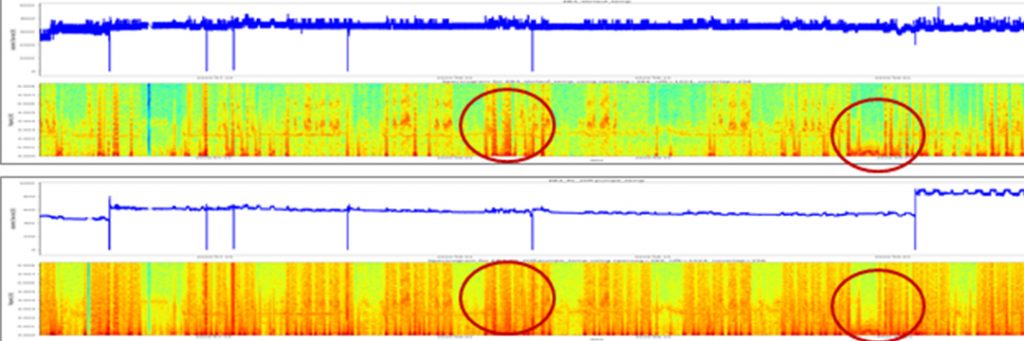
- Visualisierung und Interaktion: Fachgerechte Darstellung für den technischen Spezialisten und interaktive Markierung tatsächlicher Störungen.
- Erklärung und Diagnose: Identifizierung relevanter Einflussgrößen und Hinweise zu möglichen Zusammenhängen mit den Anomalien.
- Justierung und Training: Nutzung des Spezialisten Feedbacks für Justierung der Erkennung und Training der Verfahren.
Tatsächlich sind in den meisten Fällen viele Faktoren zu berücksichtigen. Daher sieht die AIM sowohl standardisierte Predictive-Maintenance-Lösungsbausteine vor als auch die Integration des Domänenwissens der Fachspezialisten, um in kleinen Schritten zügige Zwischenergebnisse zu liefern, die möglichst schnell produktiv genutzt werden können.